vLLM Semantic Router
![]()
![]()
An intelligent Mixture-of-Models (MoM) router that acts as an Envoy External Processor (ExtProc) to intelligently direct OpenAI API requests to the most suitable backend model from a defined pool. Using BERT-based semantic understanding and classification, it optimizes both performance and cost efficiency.
🚀 Key Features
🎯 Auto-selection of Models
Intelligently routes requests to specialized models based on semantic understanding:
- Math queries → Math-specialized models
- Creative writing → Creative-specialized models
- Code generation → Code-specialized models
- General queries → Balanced general-purpose models
🛡️ Security & Privacy
- PII Detection: Automatically detects and handles personally identifiable information
- Prompt Guard: Identifies and blocks jailbreak attempts
- Safe Routing: Ensures sensitive prompts are handled appropriately
⚡ Performance Optimization
- Semantic Cache: Caches semantic representations to reduce latency
- Tool Selection: Auto-selects relevant tools to reduce token usage and improve tool selection accuracy
🏗️ Architecture
- Envoy ExtProc Integration: Seamlessly integrates with Envoy proxy
- Dual Implementation: Available in both Go (with Rust FFI) and Python
- Scalable Design: Production-ready with comprehensive monitoring
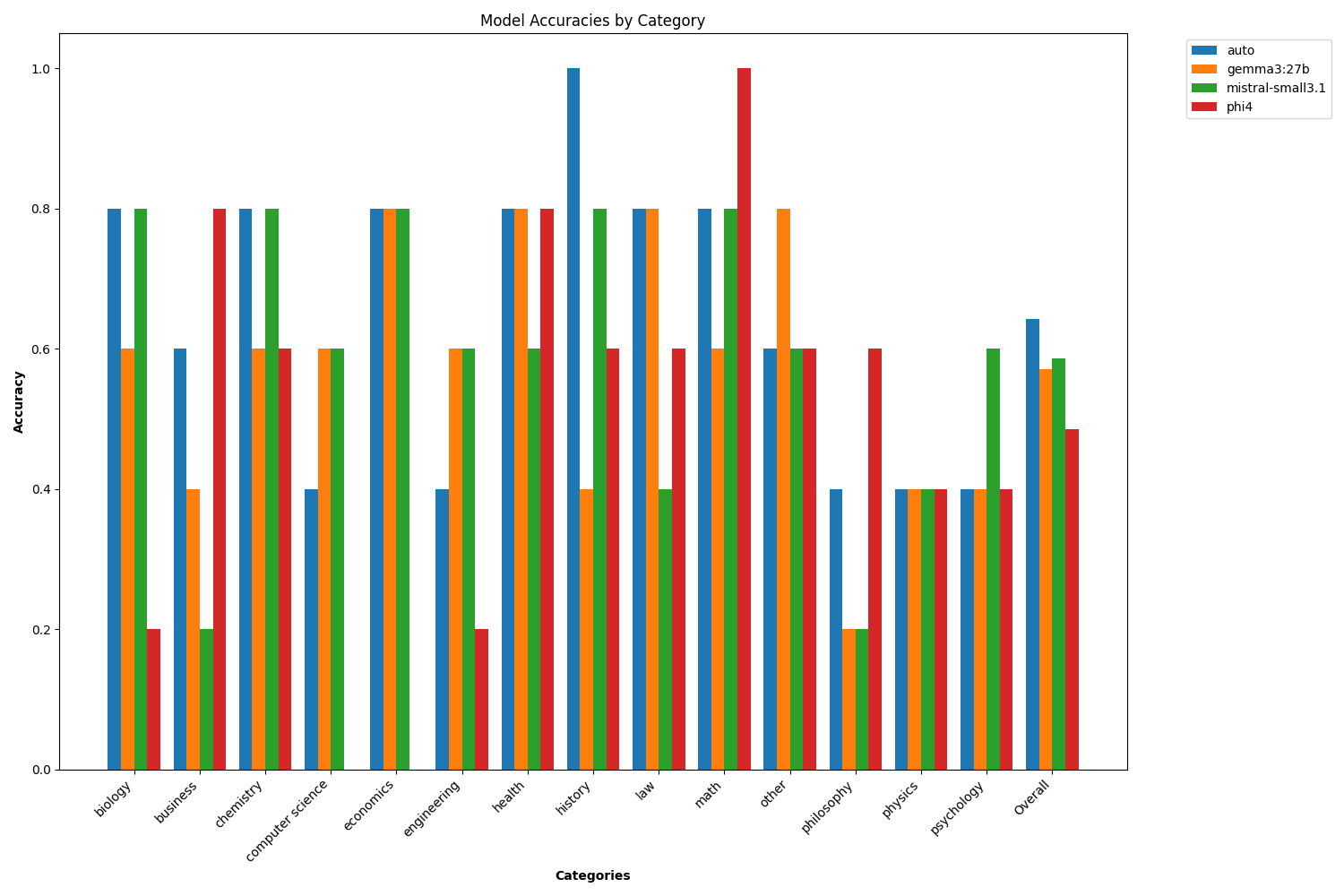
📊 Performance Benefits
Our testing shows significant improvements in model accuracy through specialized routing:
🛠️ Architecture Overview
🎯 Use Cases
- Enterprise API Gateways: Route different types of queries to cost-optimized models
- Multi-tenant Platforms: Provide specialized routing for different customer needs
- Development Environments: Balance cost and performance for different workloads
- Production Services: Ensure optimal model selection with built-in safety measures
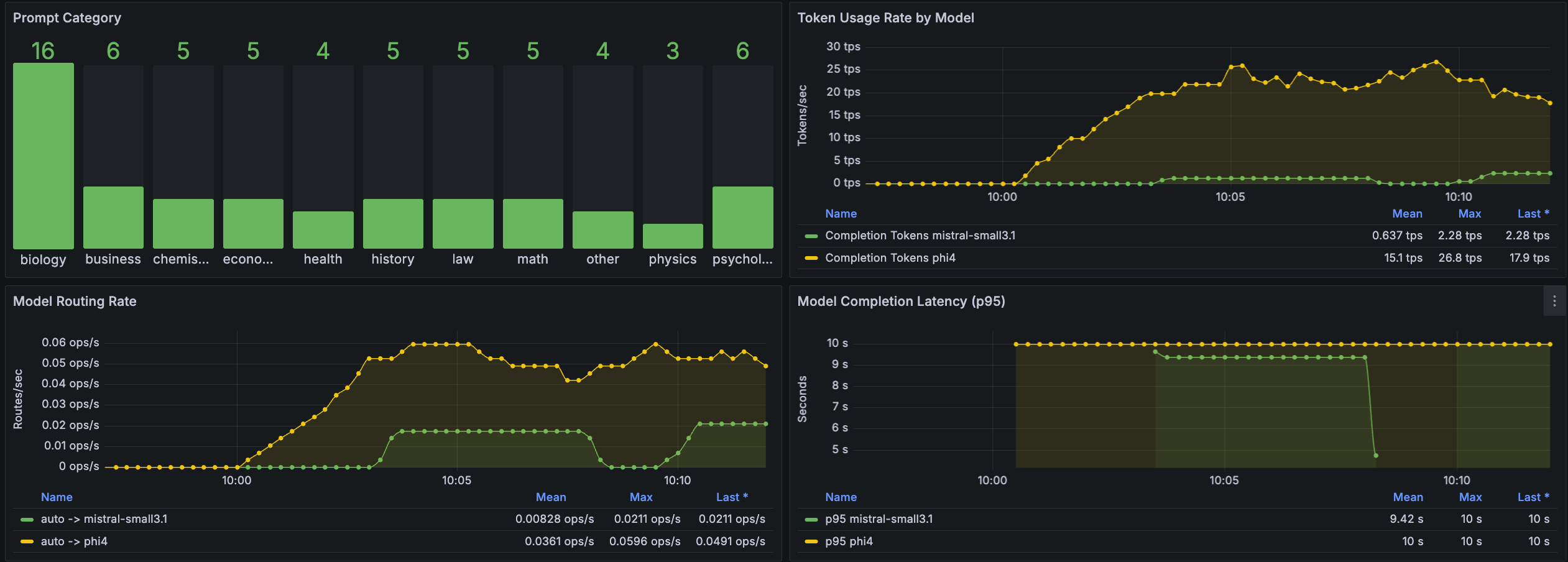
📈 Monitoring & Observability
The router provides comprehensive monitoring through:
- Grafana Dashboard: Real-time metrics and performance tracking
- Prometheus Metrics: Detailed routing statistics and performance data
- Request Tracing: Full visibility into routing decisions and performance
🔗 Quick Links
- Getting Started - Setup and installation guide
- Overview - Deep dive into semantic routing concepts
- Architecture - Technical architecture and design
- Model Training - How classification models are trained
📚 Documentation Structure
This documentation is organized into the following sections:
🎯 Overview
Learn about semantic routing concepts, mixture of models, and how this compares to other routing approaches like RouteLLM and GPT-5's router architecture.
🏗️ Architecture
Understand the system design, Envoy ExtProc integration, and how the router communicates with backend models.
🤖 Model Training
Explore how classification models are trained, what datasets are used, and the purpose of each model type.
🤝 Contributing
We welcome contributions! Please see our Contributing Guide for details.
📄 License
This project is licensed under the Apache 2.0 License - see the LICENSE file for details.